Machine Learning
Introdução
Machine learning é um subcampo da inteligência artificial que envolve o uso de algoritmos e modelos estatísticos para permitir que sistemas de computador melhorem seu desempenho em uma tarefa específica por meio de experiência, ou seja, dados. A chave é a aprendizagem automática sem ser explicitamente programada para realizar aquela tarefa.
O objetivo do machine learning é desenvolver modelos que possam fazer previsões ou tomar decisões com base em dados, identificando padrões ou insights que seriam inacessíveis ou muito complexos para serem derivados por intervenção humana ou métodos tradicionais de programação.
Tipos de Machine Learning
Aprendizado Supervisionado: Os algoritmos são treinados usando um conjunto de dados rotulados. O modelo aprende a partir de entradas e saídas já conhecidas para fazer previsões ou avaliações em dados não vistos. Exemplos incluem classificação (por exemplo, spam ou não spam) e regressão (por exemplo, previsão de preços de casas).
Aprendizado Não Supervisionado: Neste caso, os algoritmos são aplicados a dados que não possuem rótulos prévios. O modelo tenta entender os padrões e a estrutura dos dados para realizar tarefas como agrupamento ou redução de dimensionalidade. Exemplos incluem clusterização de clientes em segmentos de mercado e detecção de anomalias.
Aprendizado por Reforço: O modelo aprende a tomar decisões sequenciais. Ele recebe recompensas ou punições por suas ações em um ambiente dinâmico e busca maximizar alguma noção de recompensa cumulativa. É amplamente usado em áreas como jogos, robótica e navegação de veículos autônomos.
Aplicações
Reconhecimento de Imagem e Visão Computacional: Usado para identificar objetos e pessoas, classificar imagens, sistemas de vigilância, e veículos autônomos.
Processamento de Linguagem Natural (PLN): Aplicado em tradução automática, assistentes virtuais, análise de sentimentos, e chatbots.
Recomendação de Produtos: Sistemas de recomendação como os usados por serviços de streaming e e-commerce para sugerir itens com base no histórico e preferências do usuário.
Diagnóstico Médico: Algoritmos de machine learning podem ajudar a detectar doenças e condições a partir de imagens de raio-x, resultados de testes, e dados de saúde dos pacientes.
Finanças: Avaliação de risco de crédito, detecção de fraudes em transações, e negociação algorítmica.
Aprendizado Supervisionado
Conceito e Características:
No aprendizado supervisionado, o objetivo é desenvolver modelos que possam fazer previsões precisas com base em dados de entrada, utilizando conjuntos de dados de treinamento onde as respostas (ou rótulos) são conhecidas.
O algoritmo é treinado em um conjunto de dados que contém entradas (também conhecidas como ‘features’ ou ‘atributos’) e as saídas desejadas (conhecidas como ‘rótulos’ ou ‘labels’). O conjunto de dados de treinamento consiste em pares de entrada-saída, onde o modelo aprende a mapear as entradas para as saídas.
A “supervisão” refere-se ao uso desses rótulos: o modelo é orientado durante o treinamento para fazer previsões corretas. O desempenho do modelo é avaliado comparando as saídas previstas com os rótulos reais.
Tipos de Problemas:
Classificação: Quando as saídas são categorias discretas. Por exemplo, determinar se um e-mail é spam ou não é um problema de classificação binária (com duas classes).
Regressão: Quando a saída é um valor contínuo. Por exemplo, estimar o preço de uma casa com base em características como área, localização e número de quartos é um problema de regressão.
Algoritmos Comuns:
Regressão Linear: Modela a relação entre uma variável dependente e uma ou mais variáveis independentes, assumindo uma relação linear entre elas. Pode ser utilizado em predição de valores contínuos (por exemplo, preços de casas, temperaturas).
Regressão Logística: Apesar do nome, é usado para classificação binária, modelando a probabilidade de uma variável dependente categórica assumir um de dois valores. Pode ser utilizado em predição de resultados binários (por exemplo, sim/não, 0/1).
K-Nearest Neighbors (KNN): Classifica novos casos com base na ‘distância’ para os casos conhecidos do conjunto de treinamento, onde K representa o número de vizinhos mais próximos a considerar. Pode ser utilizado em classificação e regressão em diversos domínios.
Árvores de Decisão: Modelo que usa uma estrutura de árvore para tomar decisões, onde cada nó representa uma característica, cada ramo representa uma regra de decisão, e cada folha representa um resultado. Pode ser utilizado em classificação e regressão, útil para modelar relações não lineares.
Máquinas de Vetores de Suporte (SVM): Busca a melhor margem de separação entre as classes, transformando os dados para um espaço dimensional maior se necessário. Pode ser utilizado em classificação e regressão, eficaz em espaços de alta dimensão.
Redes Neurais Artificiais (ANNs): Modelos computacionais inspirados no cérebro humano, consistindo de nós (neurônios) organizados em camadas. Pode ser utilizado em classificação, regressão, e uma vasta gama de outras tarefas, como reconhecimento de imagem e processamento de linguagem natural.
Métricas de Avaliação:
Para Classificação: Precisão, recall, F1-score, AUC-ROC.
Para Regressão: Erro Quadrático Médio (MSE), Erro Absoluto Médio (MAE), Coeficiente de Determinação (R²).
Processo de Treinamento e Teste:
O modelo é inicialmente treinado em um subconjunto dos dados disponíveis (conjunto de treinamento).
Após o treinamento, o modelo é testado em um conjunto de dados separado que não foi usado durante o treinamento (conjunto de teste) para avaliar sua capacidade de generalizar para novos dados.
Desafios:
Overfitting: Quando um modelo se ajusta demais aos dados de treinamento e não generaliza bem para dados novos.
Underfitting: Quando um modelo é muito simples e não consegue capturar a complexidade dos dados, resultando em um desempenho ruim tanto no treinamento quanto no teste.
O aprendizado supervisionado é fundamental no machine learning devido à sua aplicabilidade direta a muitos problemas práticos, onde se conhece o resultado desejado e se deseja produzir um modelo capaz de fazer previsões precisas para novas instâncias.
Aprendizado Não Supervisionado
Conceito e Características:
No aprendizado não supervisionado, os algoritmos exploram padrões em um conjunto de dados sem usar rótulos previamente definidos. Ao contrário do aprendizado supervisionado, onde o objetivo é prever ou classificar dados com base em exemplos conhecidos, o aprendizado não supervisionado busca identificar estruturas ocultas ou agrupamentos nos dados.
O aprendizado não supervisionado lida com dados que não possuem rótulos ou saídas conhecidas. Em vez de prever ou classificar respostas, o objetivo é explorar a estrutura dos dados para extrair informações significativas ou identificar padrões subjacentes.
Sem a orientação de rótulos, o algoritmo deve encontrar por conta própria a melhor maneira de interpretar os dados, o que pode envolver agrupar informações semelhantes, descobrir regras que descrevem dados ou reduzir a dimensionalidade para visualização ou eficiência computacional.
Tipos de Problemas:
Clusterização (Agrupamento): Segmentar um conjunto de dados em grupos com base na semelhança entre os pontos de dados. Por exemplo, identificar segmentos de clientes em um mercado com base em padrões de compra.
Redução de Dimensionalidade: Reduzir o número de variáveis aleatórias sob consideração, obtendo um conjunto de variáveis principais. Isso é útil para visualização de dados e pode melhorar a eficiência de outros algoritmos de machine learning.
Associação: Descobrir regras que descrevem grandes porções de seus dados, como pessoas que compram X também tendem a comprar Y.
Algoritmos Comuns:
K-Means: Um dos algoritmos de clusterização mais populares e simples, o K-Means agrupa os dados em K (um número pré-definido) clusters. Ele inicializa com K centros de clusters aleatórios e, então, atribui cada ponto ao cluster mais próximo, atualizando os centros dos clusters iterativamente. Pode ser utilizado para o agrupamento de dados com base em similaridade, análise de segmentação de mercado, agrupamento de documentos.
Análise de Componentes Principais (PCA): PCA é uma técnica de redução de dimensionalidade que transforma os dados para um novo sistema de coordenadas, reduzindo o número de variáveis e mantendo as que contêm a maior parte da variação nos dados. Pode ser utilizado para a redução de dimensionalidade, visualização de dados, pré-processamento para outros algoritmos de aprendizado de máquina.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Um algoritmo de clusterização baseado em densidade que pode encontrar clusters de formas arbitrárias. Ele agrupa pontos que estão próximos em regiões de alta densidade e marca pontos em regiões de baixa densidade como outliers. Pode ser utilizado em detecção de anomalias, agrupamento geográfico, identificação de agrupamentos em dados de densidade variável.
T-SNE (t-Distributed Stochastic Neighbor Embedding): T-SNE é uma técnica avançada de redução de dimensionalidade especialmente adequada para a visualização de conjuntos de dados de alta dimensão em um espaço de duas ou três dimensões. Pode ser utilizado para a visualização de dados de alta dimensão, análise exploratória de dados, identificação de padrões e agrupamentos.
Algoritmos de Associação (Apriori, FP-Growth): Algoritmos de regras de associação são utilizados para encontrar itens frequentes ou associações em conjuntos de dados, como padrões de compra em transações de supermercado. Pode ser utilizado para análise de cesta de mercado, recomendação de produtos, mineração de dados em transações.
Métricas de Avaliação:
Para Clusterização: Coeficiente de silhueta, índice Davies-Bouldin, índice Dunn, entre outros.
Para Redução de Dimensionalidade: Variância explicada (para PCA), qualidade da visualização (para t-SNE).
Desafios:
Seleção de Características: Escolher as features corretas é crucial, uma vez que dados irrelevantes ou redundantes podem distorcer os padrões naturais.
Determinação de Parâmetros: Algoritmos como K-means requerem que você especifique o número de clusters de antemão, o que pode ser difícil sem conhecimento prévio.
Interpretação dos Resultados: Os resultados do aprendizado não supervisionado podem ser subjetivos e dependem da interpretação do analista.
O aprendizado não supervisionado é especialmente útil para explorar dados quando não sabemos o que estamos procurando, ou quando queremos encontrar estruturas ou padrões ocultos nos dados que podem não ser imediatamente aparentes.
Aprendizado por Reforço
Conceito e Características:
O aprendizado por reforço é uma área da inteligência artificial onde um agente aprende a tomar decisões, executando ações em um ambiente para alcançar um objetivo ou maximizar alguma noção de recompensa cumulativa. Diferentemente do aprendizado supervisionado e não supervisionado, o aprendizado por reforço foca na interação entre o agente e o ambiente para aprender a partir dessa experiência.
Aprendizado por reforço é um tipo de aprendizado de máquina onde um agente aprende a tomar decisões sequenciais interagindo com um ambiente, de forma a maximizar alguma noção de recompensa cumulativa. O agente executa ações e o ambiente responde a essas ações e fornece recompensas.
O aprendizado é orientado por tentativa e erro: o agente experimenta diferentes estratégias e aprende com os sucessos e falhas. O foco está em aprender uma política — um mapeamento de estados do ambiente para as ações que o agente deve tomar.
Componentes Principais:
Agente: A entidade que está aprendendo e tomando decisões.
Ambiente: O mundo externo com o qual o agente interage e onde ele realiza ações.
Estado: Uma representação do ambiente em um determinado momento.
Ação: Uma decisão tomada pelo agente que afeta o estado do ambiente.
Recompensa: Um sinal imediato retornado pelo ambiente após cada ação, indicando o valor dessa ação.
Processo de Decisão de Markov (MDP):
Aprendizado por reforço muitas vezes é modelado como um Processo de Decisão de Markov, onde os resultados são parcialmente aleatórios e parcialmente sob o controle de um tomador de decisão (o agente).
MDPs são definidos por um conjunto de estados, um conjunto de ações, uma função de recompensa e um modelo de transição que define a probabilidade de transitar entre estados.
Algoritmos Comuns:
Q-Learning: Q-Learning é um método off-policy para aprender o valor de uma ação em um determinado estado. Não requer um modelo do ambiente e pode lidar com problemas com recompensas estocásticas e transições de estado. Utiliza a função Q para guiar as decisões do agente, atualizando os valores Q com base em recompensas observadas. Pode ser utilizado em problemas de decisão sequencial, desde jogos simples até robótica.
Deep Q-Networks (DQN): DQN é uma extensão do Q-Learning que utiliza redes neurais profundas para aproximar a função Q. Introduzido pela DeepMind, o DQN foi capaz de alcançar desempenho humano em vários jogos do Atari apenas a partir dos pixels da tela. Ele incorpora técnicas como Experience Replay e Fixed Q-Targets para estabilizar o treinamento. Pode ser utilizado em Jogos, simulações, problemas de decisão complexos onde o espaço de estado é muito grande para métodos tabulares.
Policy Gradients: Métodos de gradientes de política, como o REINFORCE, aprendem diretamente uma política de ação sem necessidade de uma função de valor. Eles ajustam os parâmetros da política na direção que maximiza a recompensa esperada, utilizando gradiente ascendente. Isso permite aprender políticas estocásticas e lidar com ações contínuas. Pode ser utilizado em problemas com espaços de ação contínuos, otimização de políticas estocásticas.
Métricas de Avaliação:
A avaliação é geralmente baseada no retorno cumulativo que o agente consegue obter ao longo do tempo, que é a soma das recompensas coletadas.
Desafios:
Exploração vs. Exploração: O agente deve encontrar um equilíbrio entre explorar o ambiente para encontrar novas estratégias e explorar o conhecimento adquirido para maximizar as recompensas.
Espaços de Estado e Ação Grandes: Ambientes complexos com muitos estados e ações podem tornar o aprendizado extremamente desafiador.
Atraso nas Recompensas: As recompensas podem ser adiadas, tornando difícil para o agente identificar quais ações são verdadeiramente responsáveis pelos resultados.
O aprendizado por reforço é particularmente poderoso em domínios onde a simulação é possível e onde há uma clara definição de objetivo, mas as ações necessárias para alcançá-lo não são conhecidas de antemão e devem ser descobertas.
Descrição de um Processo de Machine Learning
Para ilustrar um exemplo prático de machine learning, vamos considerar um problema simples de classificação: prever se um e-mail é spam ou não (ou seja, um problema de classificação binária). Usaremos o algoritmo de Regressão Logística, que é comum para problemas de classificação. A regressão logística é um método estatístico utilizado para prever a probabilidade de uma variável dependente binária, baseada em uma ou mais variáveis independentes.
No contexto de classificação de e-mails como spam ou não spam, a regressão logística estima a probabilidade de um e-mail ser spam.
Passo a Passo:
Coleta de Dados:
Você precisa de um conjunto de dados de e-mails que já foram classificados como spam ou não spam. Este conjunto de dados deve ter algumas características dos e-mails, como a frequência de certas palavras, o uso de letras maiúsculas, o comprimento do e-mail, entre outras features.
Pré-processamento de Dados:
Limpeza: Remover quaisquer dados corrompidos ou pontos de dados que não contêm informações de features ou rótulos.
Codificação: Converter texto em números (por exemplo, contagem de palavras ou presença/ausência de certas palavras-chave) para que possam ser processados pelo algoritmo.
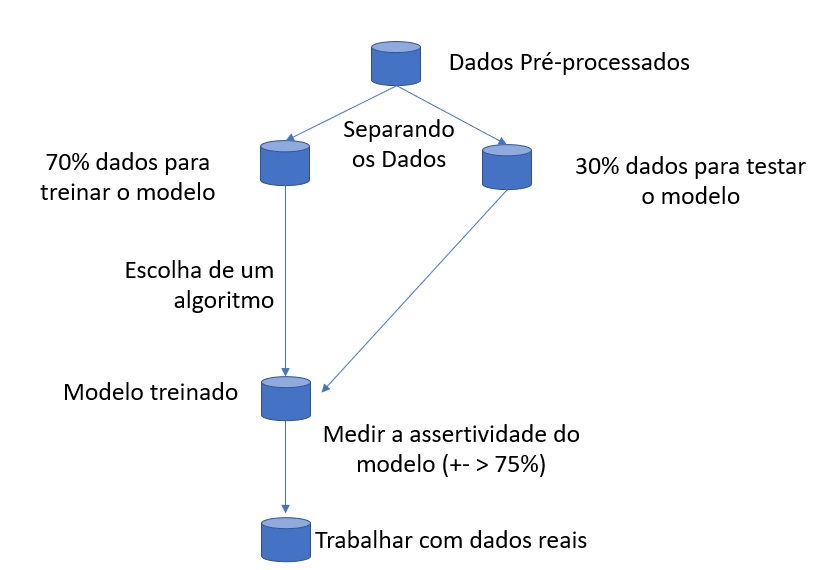
Divisão dos Dados:
Divida seu conjunto de dados em dois grupos: um para treinar o algoritmo (por exemplo, 80% dos dados) e outro para testá-lo (20% restante).
Treinamento do Modelo:
Utilize uma biblioteca de machine learning como o Scikit-learn em Python para treinar um modelo de Regressão Logística nos dados de treinamento.
Teste do Modelo:
Após o treinamento, use o modelo para prever os rótulos dos dados de teste.
Avaliação da Eficiência:
Compare as previsões do modelo com os rótulos verdadeiros dos dados de teste.
Use métricas como precisão (quantas previsões de spam foram corretas), recall (quantos e-mails de spam reais foram identificados corretamente), e a pontuação F1 (uma média harmônica de precisão e recall) para avaliar a eficiência do seu modelo.
Pombos como Especialistas em Arte
Experimento:
- Pombos em uma caixa de Skinner;
- São apresentadas pinturas de dois diferentes artistas (e.g. Chagall / Van Goch);
- Pombos recebem uma recompensa quando apresentados a um particular artista (p.e. Van Gogh)
(Watanabe et al. 1995)


- Pombos foram capazes de discriminar entre Van Gogh e Chagall com acurácia de 95% (quando foram apresentados a pinturas com as quais haviam suido treinados)
- Para pinturas dos mesmos artistas que ainda não haviam sido vistas pelos pombos a discriminação ficou em 85%.